
“Extremism in the defense of liberty is no vice. Moderation in the pursuit of justice is no virtue.” So said Barry Goldwater, running for U.S. President in 1964. At the time, the voters rejected his pitch for purity, and his opponent, Lyndon Johnson, won a greater share of the popular vote than any Presidential candidate from John Quincy Adams to Donald Trump.
Many fields gyrate at times towards extreme perspectives, and artificial Intelligence, variously known as machine learning, data science and plain old statistics, is no different. It has become characterized by widely divergent movements that tend towards intensity and purity. We briefly review two such trends that began to flourish a decade and a half ago, then focus in greater depth on a third that is now a very active topic – social activism in response to algorithmic bias.
The “Singularity” Sect
One extreme vision is of those who believe that AI will soon (in the next decade or so) surpass human intelligence and trigger the “singularity” – an event, or process, in which the future belongs to non-biological entities. Stephen Hawking said, in 2014, “Success in creating AI would be the biggest event in human history. Unfortunately, it might also be the last.” As algorithms grow in importance and complexity, the ability of software to improve itself on its own, just by reconfiguring and reoptimizing, raises the specter in some minds of a future in which the role of humans is simply to provide the hardware (at best). And manufacturing itself is increasingly automated and robotized. Hawking was worried about “technology outsmarting financial markets, out-inventing human researchers, out-manipulating human leaders, and developing weapons we cannot even understand.”
One hesitates to out-think Stephen Hawking as a futurist. However, in analyzing these speculations, it is important not to omit the “data” component of “data science.” We have already experienced decades of many futurists’ forecasts on AI falling far short. There remains virtually no evidence of AI taking off on its own to pursue goals not specified by humans, or of it acting independently of human control. Sure, there are AI systems that signal decisions that may be opaque to humans, including some that may be antithetical to what humans might have intended, but those systems can be corrected or turned off. The consistent story of AI is of it under-performing, or arriving later than expected, compared to the extravagant promises of its adherents.
The Kaggle Cult
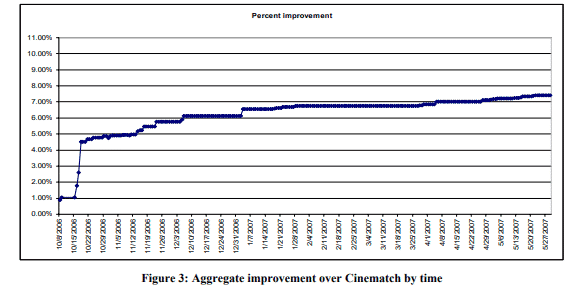
In a different direction lies the Kaggle cult. Kaggle is a platform on which highly defined machine learning challenges are openly posted, and data scientists compete to solve them. Victory is defined in a highly specific quantifiable way, so there can be no doubt as to the winner. Ironically, most of the effort expended in high profile Kaggle contests goes towards relatively minor gains as, in the later stages of a contest, competitors attempt to squeeze out ever smaller gains in predictive performance. The best-known example of this was the (pre-Kaggle) Netflix Prize, in which Netflix offered a $1,000,000 reward to the data science team that first achieved a 10% improvement in squared error over their own system’s performance in predicted movie “star” ratings. As teams worked on the project and posted their results regularly, the biggest gains were achieved early, and it became evident that further increments of progress required an extreme investment of time and effort.
One blogger described the excitement that attended the final days of the contest:
“The competition … ended in a nailbiting finish, and for a while there it seemed Bellkor [the winner] had been pipped at the post by rival team The Ensemble, who submitted an apparently superior model just 10 minutes after theirs…As it turns out though, when evaluated on the unseen validation data both models had the exact same performance, making Bellkor the winner by dint of the earlier submission.”
From a practical standpoint, the real work and value lie in the initial stages of problem formation and model fitting, plus all the work that goes into production and deployment. The “nail-biting” effort to achieve and greater accuracy is of minimal consequence. That early blast achieved most of the gain, solved most of the problem, and consumed less time and effort than the later stages. These process attributes are valuable in most business contexts, where time is money and the world is dynamic and shifting under your feet.
Nothing illustrates the futility of a lengthy pursuit of model perfection point better than the Netflix contest itself; by the time it was “solved,” the solution was inapplicable as the business itself had changed in the roughly two years that’d ensued. The ratings data had been based on DVD rentals, but during the lengthy contest, the Netflix business model had shifted towards streaming. Further, the ratings had previously been for a household as a whole but now could be tracked more by individual. Still, even without large business changes, the complexity wouldn’t be worth it.
As a Netflix executive put it,
“We evaluated some of the new methods offline but the additional accuracy gains that we measured did not seem to justify the engineering effort needed to bring them into a production environment.” (quoted by Mike Masnick in Techdirt.com)
The Silver Lining: Ensembles
My colleague John Elder points out that one lasting positive trend came to the practice of data science from the later stages of the Netflix contest: widespread awareness of the idea of ensembling competing models. As the most dedicated modelers inched near the goal it occurred to some that a share of the great prize was better than nothing, so proposing an alliance with a strong rival might be prudent. In fact, the two teams mentioned above were such super-groups. The idea was inadvertently advertised by John’s team (named Ensemble Experts by teammate David Vogel) when they debuted at 2nd place relatively early in the contest (when there were “only” 20K teams who’d submitted entries). The 3rd teammate was Jaffray Woodruff. He and Vogel were already expert data scientists and users of ensembles (in the financial and medical fields, respectively), and each now runs a large and successful hedge fund company
Cancel Culture
As tales of algorithmic bias gain ground, the stirrings of cancel culture strive for purity in yet a different direction. Strictly speaking, the term “cancel culture” usually refers to the ostracism or boycott of individual(s) who espouse views found by some to be objectionable. More broadly, it has acquired a pejorative meaning – the suppression of speech. It has found its way into data science, according to some, by those espousing the primacy of correcting for algorithmic bias – never mind model accuracy.
A government agency recently invited a wide range of scientists, activists, analysts, and policy-makers in industry, government, and academia to participate in a panel for two days to advise them on how to best evaluate systems containing AI and predictive algorithms. A fairly large part of the discussion centered around how to forcibly adjust algorithm results to ensure equal outcomes. A friend who was on the panel argued that doing everything possible to remove causes of bias is imperative of course, but forcing models to give pre-determined answers is going way too far: models must accurately reflect the information the data contains.
It could have been a richly textured and rewarding debate, except there was no debate. None of the other ~20 panelists said a word against the view that the main point of predictive modeling was to achieve equality of outcome, as if any observed difference was naturally due to bias. (One panelist proposed that the demographics of the modeler and data labeler be recorded “so we could know their biases and correct for them later.”) Will the politics of “cancel culture” be allowed to override whatever insights AI can otherwise deliver? Much depends on whether data scientists and analysts gain a deeper understanding of the different types and sources of bias in models. Only then can they effectively overcome the simplistic perspective of outcome parity. More on that later!