A famous business school case by Harvard Professor Michael Porter on forecasting chainsaw sales dramatically illustrated the limits of statistical models when common business sense and clear-eyed thinking are missing. In the chainsaw case, students were asked to forecast the future U.S. demand for chainsaws, a growing market, and assess the relative positions of different competitors with different product positionings. Typically, the students wrestle with the data and, with greater or lesser struggle, produce regression models that forecast future years’ demand for chainsaws.

The trap that most students fall into (I did!) is a multi-year forecast that eventually results in every man, woman and child in the U.S. owning at least one chainsaw. Their statistical forecast models are correct, in a limited technical sense, but the students failed to factor in market saturation and the population size.
Even in the era of powerful AI methods, the companies and agencies we at Elder Research work with want more of their employees to have common-sense Excel and “back-of-the-envelope” abilities. In short, more “data literacy” across more people.
Estimation
Probabilities (AKA risks) seem especially hard for many people to estimate. A recent Gallup survey found strikingly off-kilter estimates of Covid risks. Only 8% of adults came close to estimating the risk of serious Covid (requiring hospitalization) for the unvaccinated population. That risk is currently well below 1% (cumulative, since the beginning of the pandemic), but 1 in 3 people put it at 50%. That would mean half the unvaccinated population being hospitalized! A moment’s reflection on the people you know would quickly tell you that something is off, but nonetheless a third of the population is making an estimate that is untethered to reality.
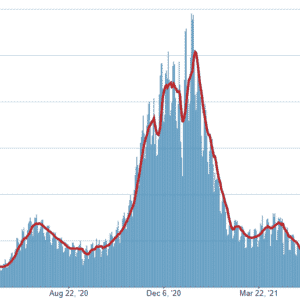
Vivid, controversial and high-profile events like Covid are especially subject to over-estimation.
In one study, participants estimated that more deaths resulted from tornadoes than from asthma; in fact asthma causes 20 times as many deaths.
A Pew Research study over a decade ago asked respondents to estimate U.S. troop deaths in the Iraq war to that point, presenting several possible answers. 57% of those answering chose overestimates while only 16% chose an underestimate. Interestingly, it did not really matter whether a person was knowledgeable about the war: those who followed it closely were just as likely to overestimate as those not following it.
Beliefs and preferences have a lot of influence. The types and directions of mis-estimation errors may, instead, be correlated with preconceived opinions. Foreign aid, for example, is unpopular and most Americans think the country spends too much on it. However, they have wildly exaggerated estimates of how much we actually spend. Survey respondents think we spend 20% of the Federal budget on foreign aid (reported in a 2015 Kaiser study); the true figure is less than half a percent.
In estimating the risk of contracting a serious case of Covid (requiring hospitalization), Republicans, who are generally more averse to vaccine mandates, better estimate Covid risks for the unvaccinated. Democrats, who tend to favor vaccine mandates, are less prone to better estimate risks for the vaccinated. (Most error comes from overestimating the risks.)
Expertise Doesn’t Always Help
The challenge of estimating probabilities affects experts as well as non-experts. In one study, 1000 doctors were asked to estimate the probability that a woman testing positive on a screening for breast cancer actually has the disease. They were given the following data:
- The prevalence of breast cancer is 1%
- The sensitivity of the test is 90% (that’s the probability that a woman with cancer will test positive)
- The false alarm rate (women without the disease testing positive) is 9%
If a woman tests positive, what is the probability that she has cancer?
The answer to this classic Bayes Rule problem is, surprisingly, 10%. Consider a sample of 1000 women: the 10% false positives among the 990 without cancer will overwhelm the 9 true positives among the 10 with cancer. Interestingly, only 21% of doctors got this right; nearly half estimated the probability of cancer at 90%.
Gerd Gigerenzer, the director of the Harding Center for Risk Literacy in Berlin, discusses this case, and many more failures of risk estimation, in his book Risk Savvy.
Data Literacy
Organizations are implementing sophisticated AI systems at an accelerated pace. Still, companies and governments are increasingly seeing the value of basic data literacy among a broader set of employees. Elder Research, best known for its careful work implementing machine learning and AI algorithms, is expanding its “data literacy” training. It is working with one state agency to establish a “data academy” to teach data wrangling and analysis skills, using Excel and SQL, to dozens of analysts. The goal is to spread analytical capability among more people, so that management’s need for answers is not constrained by analytical bottlenecks. Elder Research is also working with a major consumer packaged goods (CPG) company that sought a better understanding of the driving factors in gross profit margin. They are establishing a focused training curriculum for this company that guides analysts in both collaborative and individual work on problem formulation and analysis in an increasingly focused way.