
Dependent and Independent Variables:
Statistical models normally specify how one set of variables, called dependent variables, functionally depend on another set of variables, called independent variables. While analysts typically specify variables in a model to reflect their understanding or theory of “what causes what,” setting up a model in this way, and validating it through various metrics, does not, by itself, confirm causality. The term “(in)dependent” reflects only the functional relationship between variables within a model. Several models based on the same set of variables may differ by how the variables are subdivided into dependent and independent variables.
Alternative names for independent variables (especially in data mining and predictive modeling) are input variables, predictors or features. Dependent variables are also called response variables, outcome variables, target variables or output variables.
The terms “dependent” and “independent” here have no direct relation to the concept of statistical dependence or independence of events.
For example, a simple linear regression model states a linear relationship between the body weight ![]() and body height
and body height ![]() , and the weight is considered the dependent variable:
, and the weight is considered the dependent variable:
where ![]() and
and ![]() are parameters of the model.
are parameters of the model.
At the same time, another reasonable model may consider body height ![]() as the dependent variable and the weight
as the dependent variable and the weight ![]() as the independent variable:
as the independent variable:
where
 and
and  are parameters of the second model.
are parameters of the second model.
In other words, the models explain the value of the dependent variable by values of the independent variables. Therefore, independent variables are often called predictor variables or explanatory variables.
In general, statistical models state some functional relationship between dependent variables and independent variables in the following form:
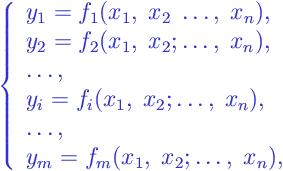 |
where
 are dependent variables;
are dependent variables;- are independent variables;
 are functions of the independent variables, usually including random terms simulating statistical uncertainty.
are functions of the independent variables, usually including random terms simulating statistical uncertainty.
See also: linear regression , loglinear regression , logistic regression , multiple regression , non-parametric regression .