In 2008, Elon Musk was concerned about leaks of sensitive information at Tesla Motors. To catch the leaker, he prepared multiple unique versions of a new nondisclosure agreement he asked senior officers to sign. Whichever version got leaked would reveal the leak source. This is known as a “canary trap.” The canary trap only works prospectively, and only for the document serving as bait, and relies on a unique match of certain details. It failed for Elon Musk because one of his team recirculated their particular version to everyone, allowing all recipients to notice the unique tweaks. Text mining methods allow greater flexibility. For example:
- In a situation where the leaker modifies or paraphrases the information so that an exact match is not possible. You have a set of documents and you want an algorithm that can discover internal documents closely related to the leaked documents.
- Or consider the problem of legal discovery, where a law firm receives hundreds of thousands of “relevant” documents during the discovery process. Going through the documents is extremely time consuming and expensive, but the firm does have a limited set of “known relevant” documents and descriptions – it needs an algorithm that can go through the hundreds of thousands of documents and locate those that are closely related.
In text mining this is known as a “corpus-to-corpus” comparison; a corpus is a defined body of documents (often used to train a text mining algorithm). Let’s review how this comparison process might be automated.
Quantifying Text
The first step in preparing text for comparisons like this is to turn the text data into numeric data – specifically a matrix in which each row is a word, and each column is a document. Each cell entry is a 0 or 1, depending on whether the word is present in that document or not, or a number representing the frequency of that word in the document. This vectorization of documents is the “bag of words” approach – order does not matter and we are simply noting the presence or frequency of words in a document.
Pre-processing
If a document consisted solely of words separated by spaces, a simple algorithm could turn a document into a numeric vector, and multiple documents into a matrix. This is rarely the case – the rules required to parse data from real sources need to be more complex, accounting for punctuation, non-alpha characters, capitalization, emojis, and more. The rules produce “tokens,” the end unit of analysis – rows will consist of tokens, as opposed to words. A word separated by spaces is a token. For example, 2+3 would be separated into 3 tokens, 23 would stand as one token. Punctuation might stand as its own token. For large documents tokenization produces a huge number of tokens which need to be reduced before beginning analysis. Some off-the-shelf reduction methods include:
- Stemming to reduce different variants of words (e.g. reduce, reduces, reduction) to a single stem
- Consolidating synonyms
- Stopword lists to define tokens to eliminate (e.g. prepositions, or terms that appear in nearly all documents and do not serve to distinguish)
- Ignoring case
TF-IDF Matrix
In clustering or classifying documents, terms that rarely appear in any document are not that useful. Nor are terms that are ubiquitous. Most useful are terms that appear with frequency in some but not most documents. The metric that captures this is Term Frequency – Inverse Document Frequency (TF-IDF). There are several ways to calculate TF-IDF, but the idea is that the more frequent a term is in a document, and the fewer the documents that have that term, the higher TF-IDF. So instead of the document vector representing term presence or absence with 0’s and 1’s, or frequency with a count, each element in the document vector is the TF-IDF score. For a corpus of multiple documents, we have the TF-IDF matrix.
Text Mining
Having quantified and reduced the text, and prepared the TF-IDF matrix, we’re ready to proceed with text-mining:
- Classifying documents – the training data has a classification of each document (relevant or not relevant), from which a model learns to classify new unknown documents
- Clustering documents – finding clusters of documents that are similar to one another
Classification techniques use training data for which each document’s label – the target variable – is known. This target variable is usually binary (e.g. relevant or not relevant), but could be multi-category, or a numerical score. The TF-IDF values are the predictor values, so now our data set is completely numeric (or categorical) and can be used by a variety of predictive models. These models will produce probabilities of belonging to particular categories, which can be used to classify new documents lacking labels.
Clustering techniques are an unsupervised process – finding groups of documents that are close to one another, with no training process to assign labels. The same vector representations of documents (i.e. TF-IDF vectors) are used, and distances between documents are calculated. Various distance metrics and cluster algorithms are used to identify clusters, just as with purely numeric data.
Combining Clustering with Graph Data
The following visualization of “corpus to corpus” comparison shows a hybrid approach that was recently brought to my attention by John Dimeo, Software Architect at Elder Research. We’re interested in looking beyond naturally occurring clusters and discovering more information than a simple binary label.
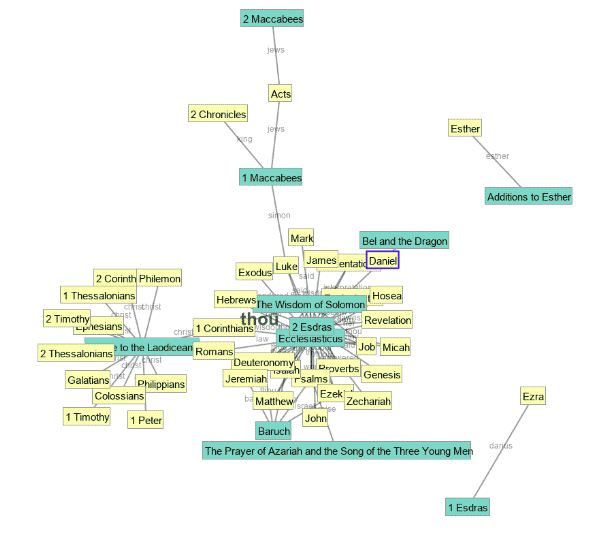
The graph illustrates linkages among similar biblical texts – links are shown between a canonical text (yellow) and the Apocryphal text it is closest to (blue). Apocrypha are works that were not in the Hebrew bible but appeared in early Greek and Latin translations. The term most in common between two closely linked texts is shown in a light gray. Of interest is the question
“Which Apocryphal texts are closest to the canonical biblical texts?”
From the plot you can see that three or four Apocryphal texts (“The Wisdom of Solomon,” “2 Esdras,” “Ecclesiasticus,” and, to some degree, “Baruch”) share common proximity to 24 canonical texts that include the four gospels. Another, “Epistle to the Laodiceans,” is close to 11 different canonical texts. These are the main relationships; other individual and small clusters are revealed (e.g. Ester and its additions are in their own cluster).
Note that both document labels and document clusters are products of this analysis. However, this is not a pure classification problem, where we train a model to classify a document based on labeled data. Nor is it a standard unsupervised clustering problem, where we identify naturally-occurring clusters. Rather, the goal is to identify clusters of documents in a target corpus that are close to documents in a source corpus, where multiple source clusters might also surface.
Biblical text analysis is more of a research application than a typical data science problem, but for some data science applications this hybrid clustering + classification approach provides useful additional information and perspective:
- Identifying the source of leaked documents would benefit from learning whether there are clusters of unleaked documents that are similar to the leaked documents. This might suggest whether there are multiple sources, or shed light on the distribution channel.
- Legal or forensic analysis of documents would also be enriched by going beyond classifications of “relevant/irrelevant,” by identifying groups of documents that may be similar to other groups of documents. This might inform analysis of which people or offices should be researched or investigated.
- Identifying groups of patient records (physician descriptions of symptoms) that are similar to a target group of records with known diagnosis might be helpful in identifying and controlling epidemics. Automated reporting, provided enough providers participate, could allow public health authorities to go beyond the diagnosed and confirmed cases of an outbreak and identify others who may have the disease.