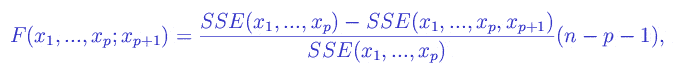In regression analysis, variable-selection procedures are aimed at selecting a reduced set of the independent variables – the ones providing the best fit to the model.
The criterion for selecting is usually the following F-statistic:
where n is the total number of data points, SSE is the sum squares due to error – that is, the sum of squares minimized by the least squares method. If adding the variable xp+1 to variables x1,…,xp does not improve (or deletion of the variable xp+1 does not worsen) the fit significantly, this statistic follows an F-distribution; otherwise, the statistic tends to take on larger values.
Planning on taking an introductory statistics course, but not sure if you need to start at the beginning? Review the course description for each of our introductory statistics courses and estimate which best matches your level, then take the self test for that course. If you get all or almost all the questions correct, move on and take the next test.
Data Analytics
Considering becoming adata scientist, customer analyst or our data science certificate program?