In 2009, China began regional pilot programs that repurposed credit scores to a broader purpose – scoring a person’s “social credit.” 100 years earlier, at the height of the eugenics craze, the famous statistician Francis Galton undertook to repurpose statistical concepts in service of social engineering.
The starting point was a social survey of London by Charles Booth. Booth was heir to a shipping fortune, and passionately interested in social reform. In the 1890’s, he published a study of class and wealth that included a map of London, color-coded to show where different classes of residents lived.
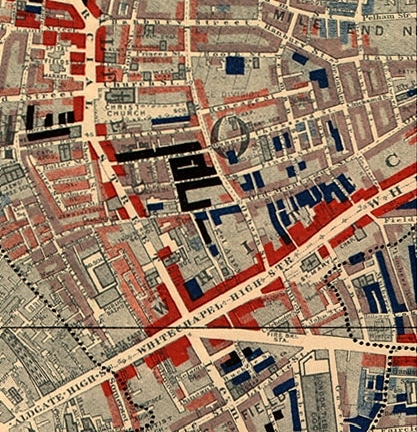
Booth’s map of the Whitechapel area of London, red = prosperous, black = poor
Source: MacKenzie, see below
Galton, known now for his development work on regression, correlation, the normal distribution and more, took Booth’s social categories and added statistical analysis in his 1909 Essays in Eugenics.
It was in these essays that Galton set forth what Donald MacKenzie termed “the most explicit statement … of the eugenic theory of society” (Statistics in Britain, 1865-1930).
Galton believed that each person possessed a fixed, inherited quantity of “civic worth.” Those with a large quantity lived prosperous lives as industrialists and independent professionals, or, just one rung down, skilled tradesmen and clerks. Those with very little civic worth, characterized by “shiftlessness, idleness or drink,” were paupers, criminals and other “undesirables.”
Galton believed that civic worth was a quantitative variable that was genetically determined (he called it “genetic worth”) and normally distributed:
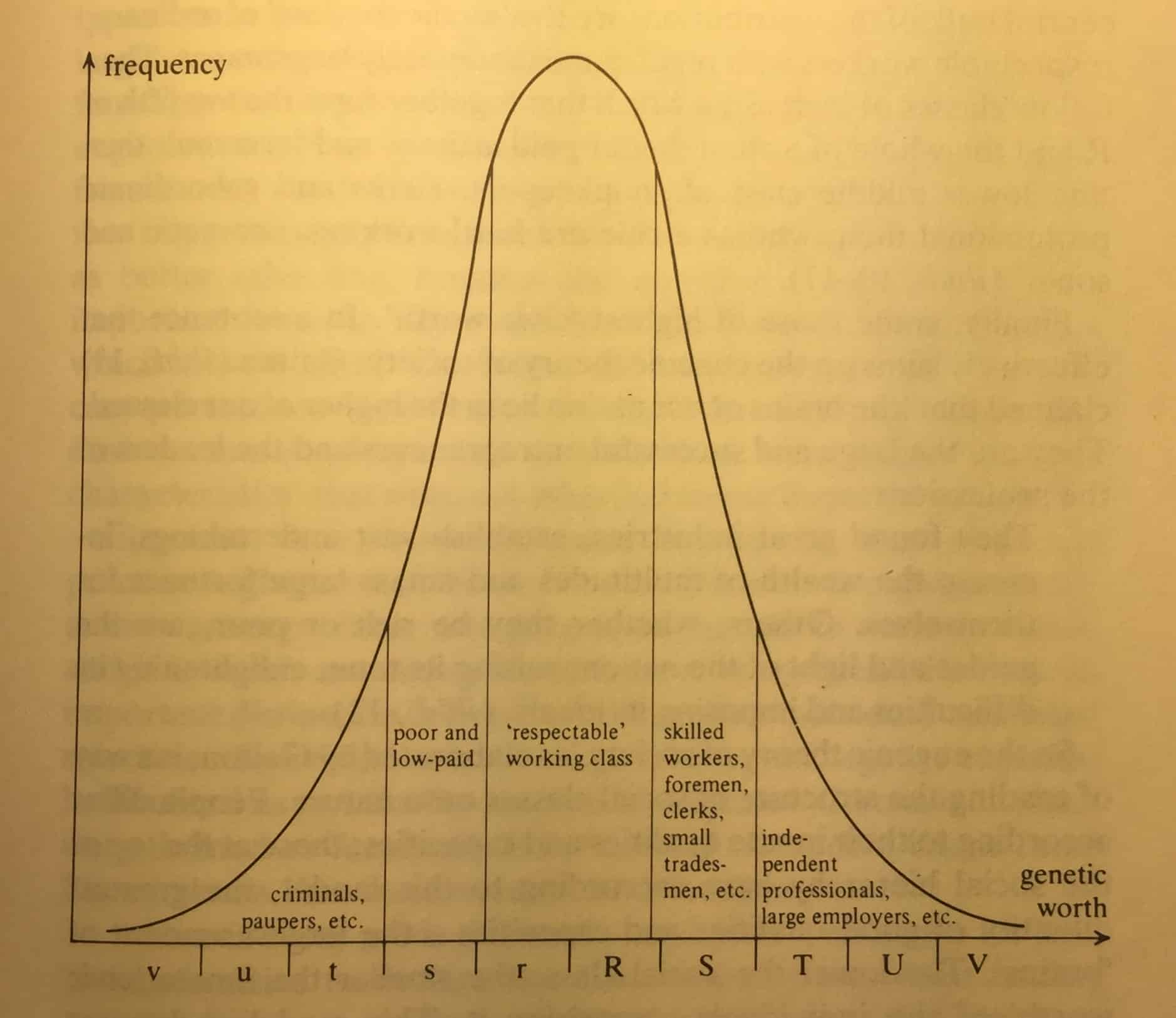 Source: MacKenzie, see above
Source: MacKenzie, see above
Leading eugenics proponents like Galton thought of themselves as social reformers. They favored policies, as Leonard Darwin (son of Charles) put it,
To promote the fertility of the better types which the nation contains, whilst diminishing the birth rate amongst those which are inferior
For example, among the “inferior” types, males and females could be kept segregated to prevent them from having children and propagating inferiority. At the other end of the scale, eugenicists advocated bonuses for having children, bonuses that increased the further up the socio-economic scale one ascended.
As repellent as this sounds to the modern ear, at the time it was mainstream liberal thinking. The founding fathers of statistics (Pearson, Fisher, Gosset, in addition to Galton) were among the leading lights of the eugenics movement. Founders of the socialist Fabian Society, including H. G. Wells, George Bernard Shaw and the Webbs, were also adherents.
Although eugenics traveled under the banner of science, it relied on pure supposition – there was no foundation in evidence for the notion of a quantifiable “civic worth” that was inherited, let alone for the proposition that it was normally distributed and could be manipulated at a population level.
Intelligence
The statisticians leading the movement soon became aware of the limitations of the metric “civic worth” – it was a fuzzy concept and hard to measure. As a result, they shifted to the notion of “intelligence,” which could be measured in an IQ (intelligence quotient) test and, as it turned out, was normally distributed. Or so they thought (and many still think today). That there is an intuitive concept of “intelligence” is indisputable, but there is much debate about whether the concept is adequately defined and measured by standard IQ tests. (To delve into the science of how to model constructs that are not directly measurable, see our courses Introduction to Structural Equation Modeling and Structural Equation Modeling in R.)
In any case, the idea that IQ is normally distributed is a chimera. IQ scores are normally distributed, yes, but that is because IQ tests, as a social convenience, are engineered to produce scores that are normally distributed. If the tests produce too many scores at the “intelligent” end of the scale, test engineers add harder questions and drop easy ones. If the tests skew in the opposite direction (too “unintelligent”), the engineers add more easy questions and drop some hard ones. The fine tuning proceeds until a nicely shaped normal curve results.
Eugenics Discredited
Although some contemporaries of Galton balked at the implications of eugenics-guided breeding, it was not until the ideas were taken to extreme conclusions by the Nazis that the whole idea was discredited. The scholarly journal Annals of Eugenics continued to be published until 1954, when it changed its name to the Annals of Genetics.
The Normal Distribution
A noteworthy aspect of Galton’s work was his extension of the domain of the normal curve. The normal distribution was originally called the “error distribution” and it referred not to the distribution of data, but the distribution of measurement errors. Galton was not the first to apply it to naturally-occurring data in addition to measurement errors, but his work considerably advanced the perception of the normal curve as representing the usual distribution of measured data in nature. The normal distribution proved extremely useful in the era of mathematical statistics, as it could be used to take analysis out of the realm of (messy) data and render it a matter of calculation. In the era of computational statistics, this advantage matters little, and can be counterproductive in shifting attention away from the data. The term “normal,” by the way, was originally applied in its geometric sense (perpendicular or orthogonal). It meant nothing about the typical or usual state of data.
Social Engineering via Data Science Today
Fast forward 100 years, and we again see statistics – or, more precisely, data science – being pressed into the service of social engineering. The Chinese extension of financial credit scores to the notion of “social credit” starts small. Train fare evaders, for example, can be denied passage on railways (and who would question the right of a railway to do this?) In China, however, the all-seeing role of the government can raise this punishment to a society-wide level. Business Insider reports that residents can earn social credit demerits through bad driving, smoking in non-smoking zones, buying too many video games and posting fake news online. Punishment can take the form of withdrawing privileges such as the right to apply for good jobs, stay in good hotels, enjoy high speed internet, and more. Social credit disgrace can spread to one’s family – a parent’s wayward post on Weibo might result in their kids being denied entry to good schools,
Media accounts do not make clear exactly how AI and data science algorithms fit in, but it is not hard to imagine. Predictive algorithms can be used to adjust and tune rule-based systems of assigning social credit scores. For example, they can allow the state to sanction behaviors that are not themselves overtly objectionable, but may be predictive of behaviors that are (similar to the more benign case of using such models to predict which students are most prone to academic failure and dropping out). Network analysis could be used to predict how negative social behavior might spread to individuals who are not yet under suspicion, and assign them scores as well. Image recognition algorithms are already being deployed on a wide scale to enable location tracking and more rapid enforcement.
Implementation of this Orwellian world in China has initially lagged behind what some press accounts have suggested. Louise Matsakis in Wired writes that the program of social credit scoring is actually less sweeping and more sporadic than was initially supposed. However, these limitations seem to be more temporary problems of implementation rather than overall design limits.