The Three Stooges comedy sketch “Ants in the Pantry,” (1935), features the Stooges as exterminators whose target customers don’t have enough pests.

The Stooges solve the problem by bringing their own pests (ants and mice) on sales calls, and surreptitiously releasing them. Having created the demand, the Stooges are in a perfect position to exploit it (though, being Stooges, they of course bungle the opportunity).
In statistics, altering the data to make the analysis come true is, unfortunately, an old practice. One storied case of likely academic fraud concerns the British IQ researcher Cyril Burt.
The Burt Affair
Cyril Burt, born in 1883, started his career as a school counselor. Part of his responsibility was to identify “feeble-minded students,” so they could be segregated, per the requirements of the “Mental Deficiency Act of 1913.” In the photo below, he is shown assessing the speed of a child’s thoughts.
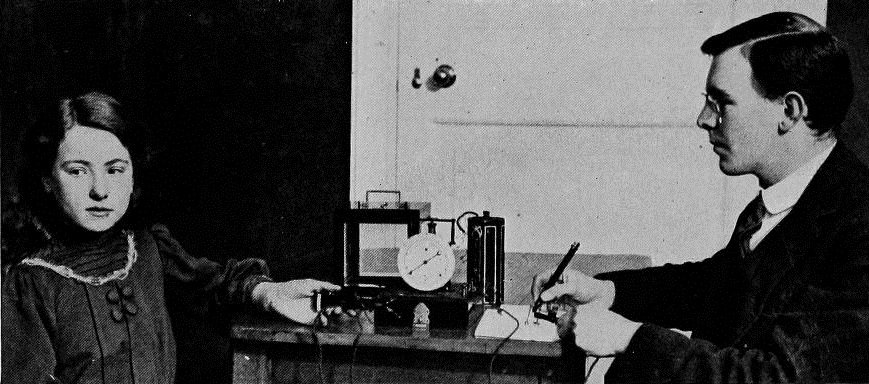
Burt went on to study the hereditary component of IQ by testing identical twins, and his research became famous. It also became infamous: later researchers noted that, as Burt added data to his original study, his published correlation coefficients of twin IQ’s remained identical, to three decimal places. The suggestion of fraud could not be definitively proved or disproved, since Burt’s notes were burned.
Altering Behavior to Make Predictions Come True (the “Nudge”)
Altering data to make analysis come true is fraud. Altering human behavior so that predictions come true is more nuanced, hidden, and has broader scope.
Galit Shmueli, a noted data science researcher (also the developer of our Predictive Analytics series) highlights a more specific aspect of big-tech’s capability for behavior modification: internet platforms selling predictive services can work both ends of the street and help those predictions come true.
Consider the Google Analytics metrics “Purchase Probability” and “Churn Probability,” which purport to estimate the probability that an advertising target will purchase, or that a recently-active visitor will stop visiting (churn). These predictions allow the advertiser to build target audiences for purchase offers, or to implement an intervention to bring the churner back. At the same time, Google also has the capability, through ad placement and configuration of search results, to boost the probability of purchase or reduce the probability of churn.
The advertiser would likely be pleased until another advertiser comes along who pays more, in which case Google has an incentive to downplay the first advertiser and promote the second. The predictions that did so well are now under-performing.
For internet platforms and app developers, there are lots of ways to alter consumer behavior, via a “nudge.” The term comes from a 2008 book by that name, Nudge, by Thaler and Sunstein, who describe a nudge as follows:
“A nudge … is any aspect of the choice architecture that alters people’s behavior in a predictable way without forbidding any options or significantly changing their economic incentives. To count as a mere nudge, the intervention must be easy and cheap to avoid.”
Subtle suggestions in advertising are hardly new. The use of “subliminal” clips in movies and TV (short frames that register on the subconscious but not the conscious mind) dates back many decades. In one episode of the detective show Columbo, the murderer inserts a frame of a frosty Coca Cola into a privately-screened film. The victim, having been fed salty caviar, leaves the screening room for a drink of water, whereupon he is murdered.
The idea of the nudge gained political favor early on as a form of “libertarian paternalism.” A company or a government interested in bolstering individual retirement plans might define the default plan option as “sign me up.” The employee has the option to opt out but is steered in the direction of enrolling. Nudges are not new in marketing. In the heyday of direct marketing, advertisers sending out a mail package used a number of ancillary messaging opportunities besides the body of the letter (headline in the top right corner, postscript, message below the return address on the envelope, small note that falls out of the letter urging you to do something). In the internet world, the ways to nudge are virtually unlimited: the placement of buttons, colors, use of pictures, size and placement of ad copy, etc.
In the realm of internet advertising, you can end up with two systems interacting:
- The predictive algorithm to predict what ad a person is likely to click on
- The nudge algorithm to modify the web presentation to maximize click probability
Shmueli’s paper presents a statistical methodology to isolate the effect of the nudge, depicted in the lower right of this diagram, showing how it can reduce the prediction error (diagram is from “Improving Prediction of Human Behavior Using Behavior Modification,” Galit Shmueli, August, 2020 https://arxiv.org/pdf/2008.12138.pdf):
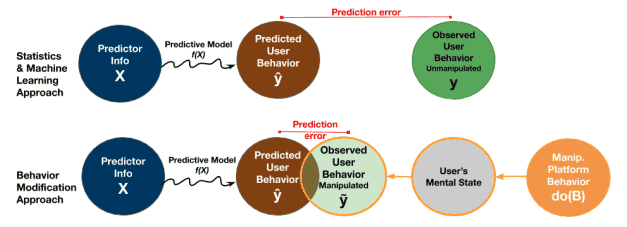
Are there examples of this happening? It would all be under the hood in a highly proprietary world, so we wouldn’t know. Shmueli cites a hypothetical example:
Suppose a financial company with a popular smartphone app wants to sell risk scores (perhaps based on their own data augmented with purchased data) to auto insurance companies. The app can then push nudges to align outcomes with scores. For example, it could offer app users with moderate to low risk scores options to decrease phone engagement during driving (e.g., limit notifications or phone calls). Perversely, for higher-risk customers, it could show ads for beer towards the end of the workday. It is hard to think that a human rules-based system would do the latter, but in a dystopian future, a fully-AI system might learn those rules on its own.
Today, the prediction and the nudge are mostly defined separately. The predictive algorithm might be something as simple as logistic regression, prized for its speed (see this article on Google’s ad display algorithm). The nudge algorithm is likely some form of a multi-arm bandit (like a dynamic A/B test with multiple things being tested).
In all likelihood, the prediction and nudge will ultimately be part of a single interdependent system, powered by AI reinforcement learning, where the system combines the predictions and the nudges to maximize click dollars. The optimal nudges are a function of the person being nudged, and the person being nudged is a function of their predicted click probability. The system (which also must take account of ad choices) would have to be solved simultaneously to be truly optimized. Human judgement and intervention would not be required.
Conclusion
The vision of a future in which our behavior is manipulated by self-learning algorithms is certainly dystopian. Many would agree with one commentator, Karen Yeung, who coined the term “hypernudge,” a phenomenon with “troubling implications for democracy and human flourishing if Big Data analytic techniques driven by commercial self-interest continue their onward march unchecked by effective and legitimate constraints.” The Shmueli paper offers a framework to judge the extent of the manipulation, at least in the context of a prediction machine.
On the other hand, if you are an optimist, you take comfort in the fact dire forecasts like Yeung’s often exhibit “regression to the mean.” You can take comfort, as well, in the knowledge that there is nothing new in big-budget behavior modification via both direct and subtle means. It’s called advertising and has been subject to critiques similar to Yeung’s over the decades.